Depth MoSeq
You can find setup instructions and tutorials on the MoSeq2 wiki
Keypoint MoSeq
For setup instructions and tutorials use the keypoint-moseq docs.
Community and Feedback
Join our Slack channel to reach out to our community ![]()
Please tell us what you think by filling out the surveys
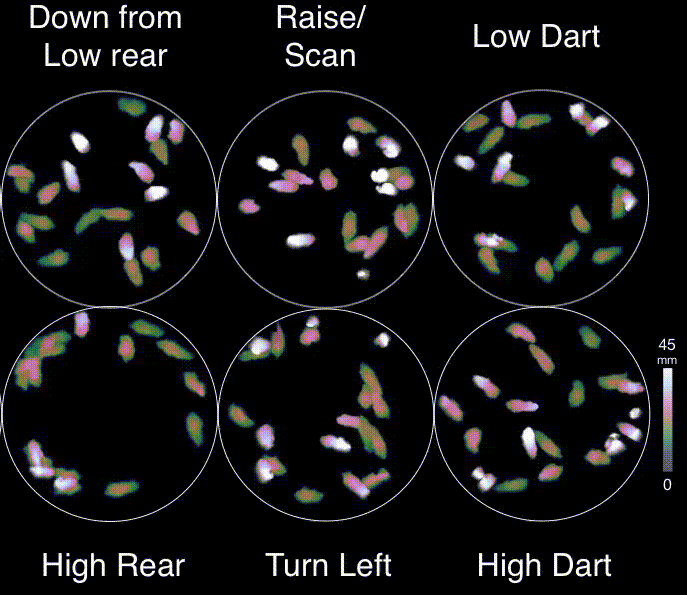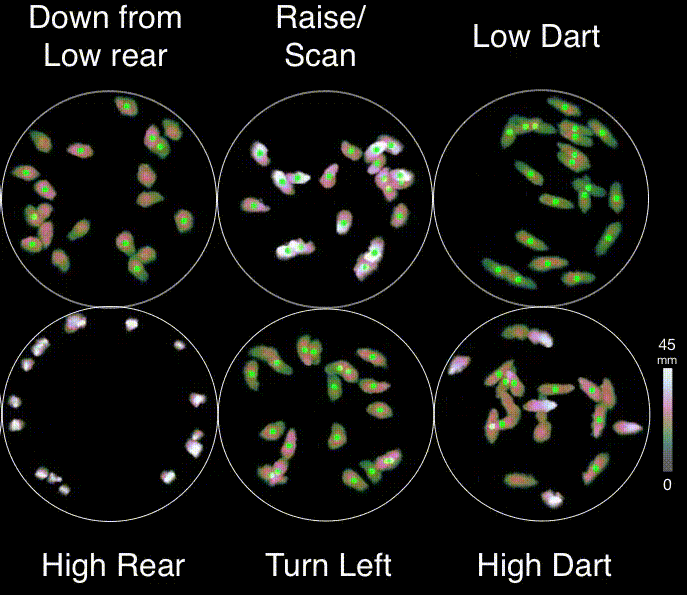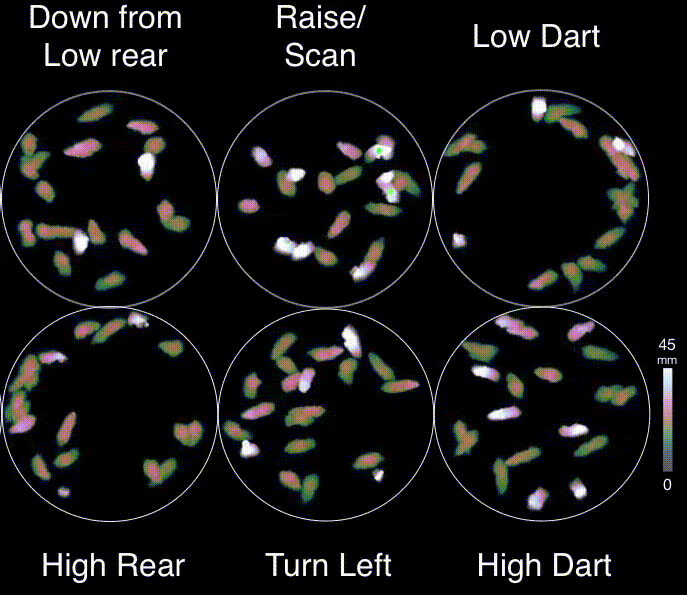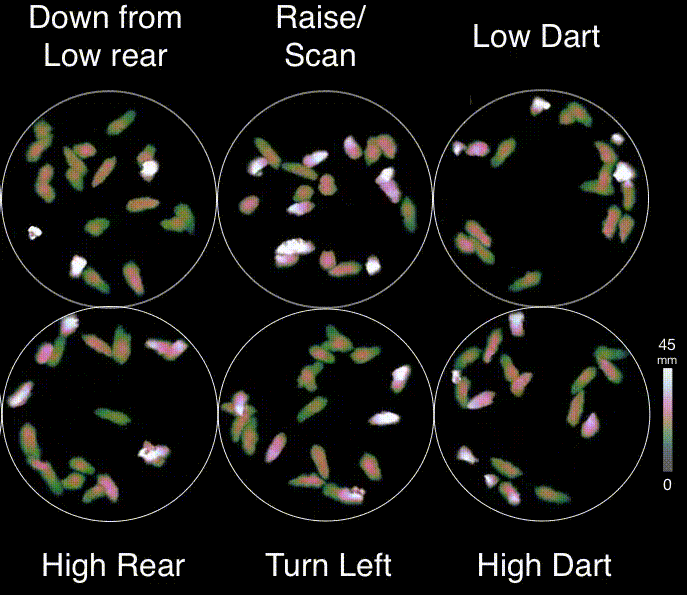
About MoSeq
Motion Sequencing (MoSeq) is an unsupervised machine learning method used to parse mouse behavior into a set of re-usable sub-second motifs called syllables (Wiltschko et al., 2015). Because MoSeq relies on unsupervised machine learning, MoSeq discovers the set of syllables and grammar expressed in any given experiment. By combining MoSeq with electrophysiology, multi-color photometry, and miniscope methods, neural correlates for syllables have recently been identified in the dorsolateral striatum (Markowitz et al., 2018).
Brief overview of Depth MoSeq Pipeline
Data extraction
MoSeq 3D depth video recordings to learn about the structure of mouse behavior. A Microsoft Kinect depth sensor acquires depth video at 30 Hz as a mouse explores a featureless arena. The MoSeq extraction step indentifies the recording arena, finds the mouse, and aligns the body to face one direction.
The gif on the right The gif below shows an example preview of the extraction step.
The mouse shown in the top left is the result of the extraction, while the bottom right section shows the un-extracted mouse running on the arena floor after background subtraction. Colors represent height from the floor.

Modeling
After extraction, a probabilistic time-series model (an autoregressive hidden Markov model, or AR-HMM) parses behavior into a set of re-usable sub-second motifs called syllables.
This segmentation naturally yields boundaries between syllables, and therefore also reveals the structure that governs the interconnections between syllables over time which we refer to as behavioral grammar.
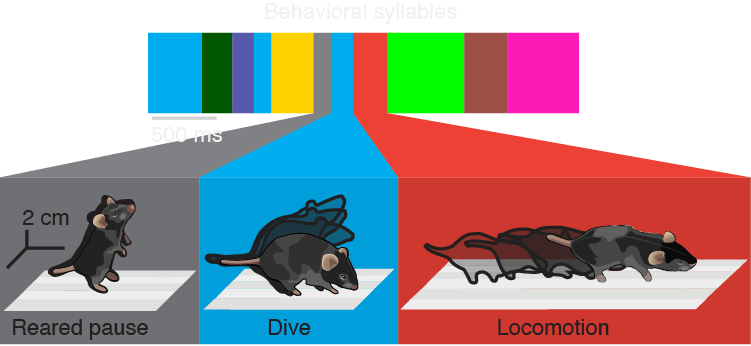
The schematic on the leftbelow shows a sequence of syllables identified by an AR-HMM, with three examples expanded.
MoSeq analysis
Syllable labeling
The Jupyter notebooks that come with the MoSeq2 package are packed with widgets and tools to help with extraction and analysis. The tool shown here makes labeling the set of syllables a model discovers a piece of cake.

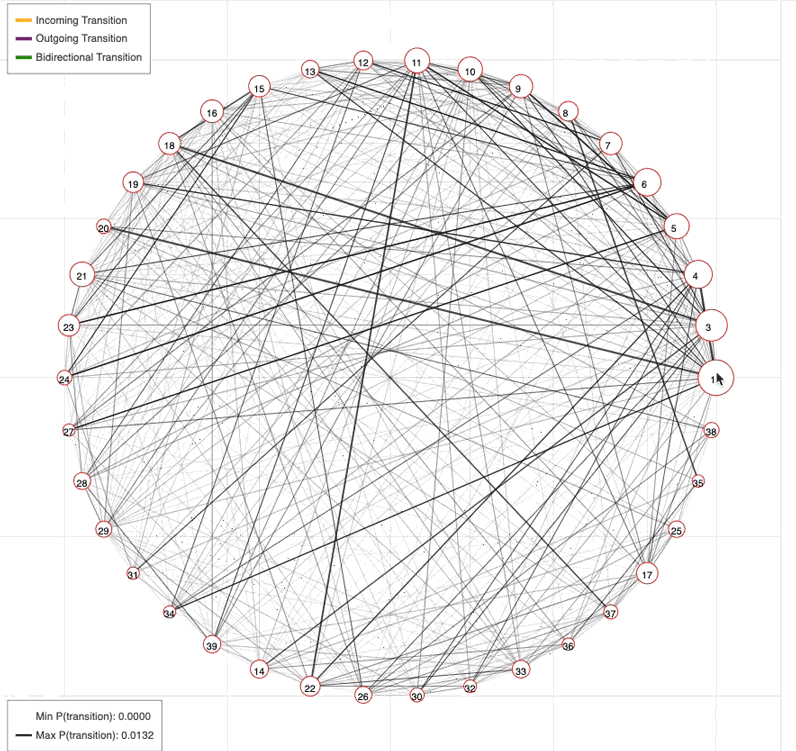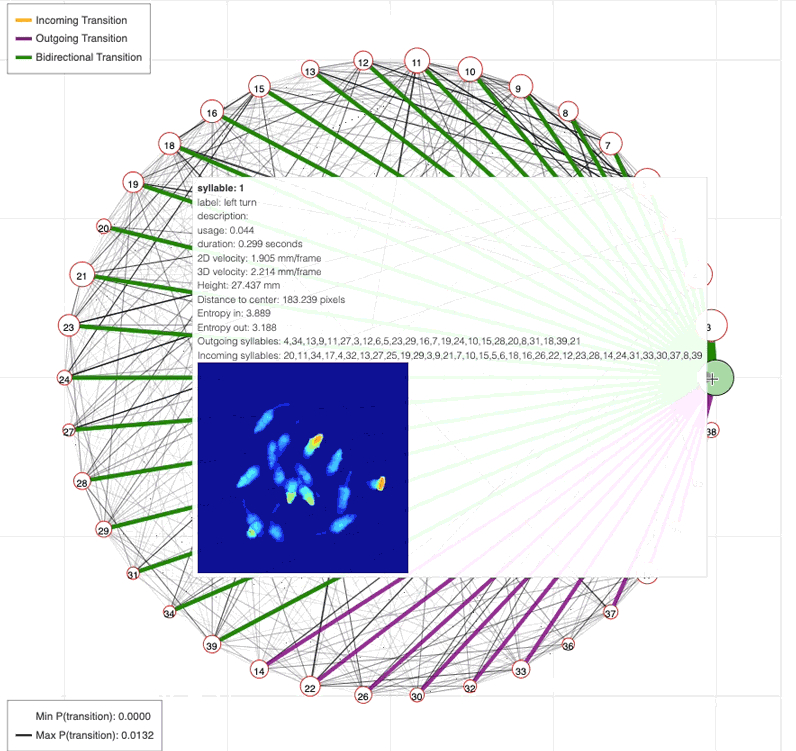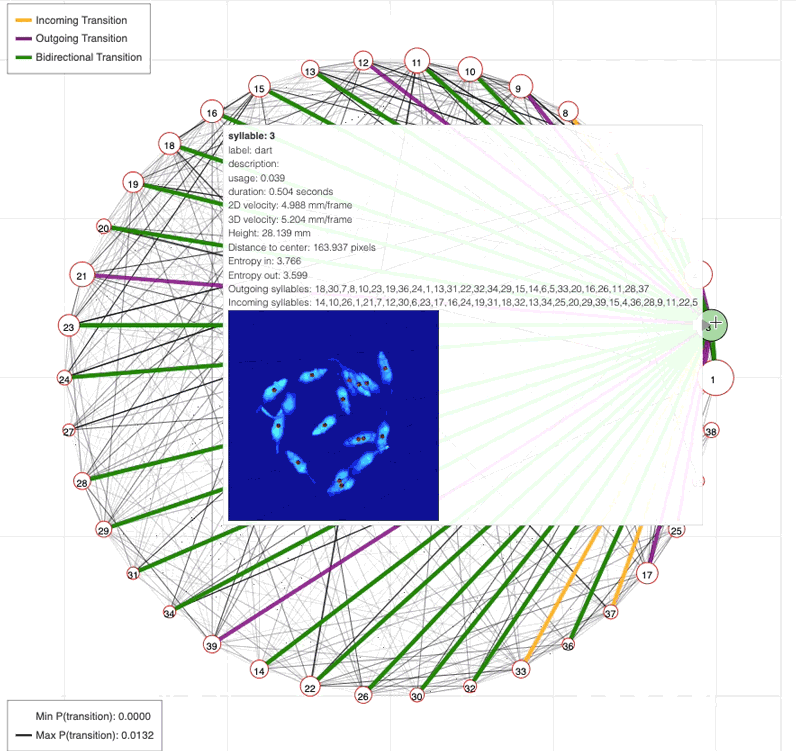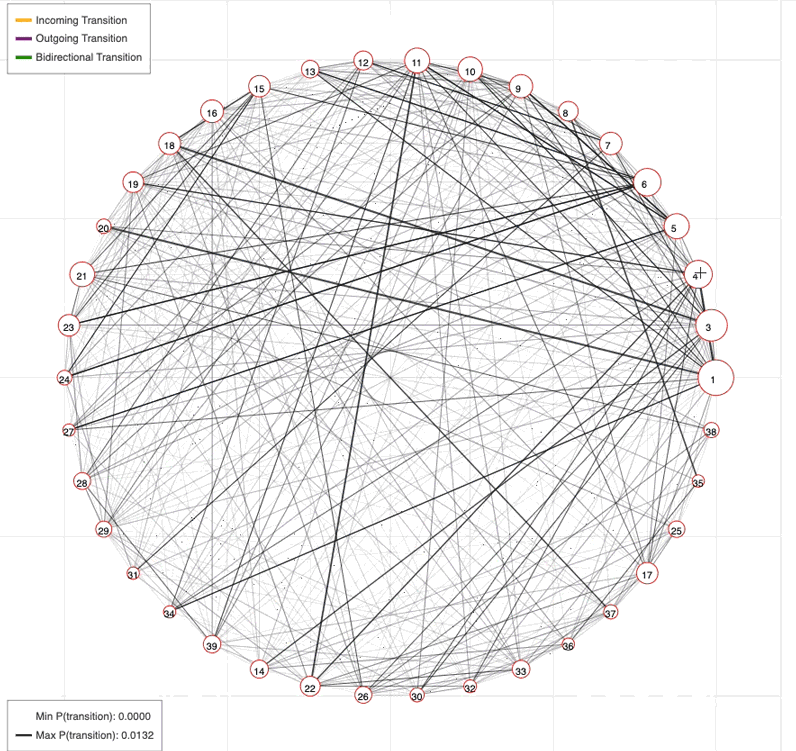
Profiling syllable transitions
Because the AR-HMM densely labels mouse behavior, every syllable instance is sandwiched between other syllables. Using this information, we can ask how often certain syllables transition between one another.
The screenshot on the left below shows a tool we use to represent and explore connections between syllables in graphical form.
Tutorials
-
Installing MoSeq on MacOS using Docker
-
Installing MoSeq on MacOS using Conda
-
Installing MoSeq on Windows using Docker
-
Installing MoSeq on Linux using Conda
-
Test datasets
Events
-
We are hosting a keypoint MoSeq tutorial workshop on Wednesday, November 8th, 2023 at 2:00-4:30PM ET.
Registration -
We are hosting a keypoint MoSeq tutorial workshop on Monday, October 9th, 2023 at 12:00-2:30PM ET.
Registration -
We are hosting a keypoint MoSeq tutorial workshop on Tuesday, September 12th, 2023 at 2:00-4:30PM ET.
Registration -
We are hosting a depth MoSeq tutorial workshop on Friday, August 11th, 2023 at 2:00-4:30PM ET.
Registration -
We are hosting a tutorial workshop on Wednesday, November 2nd, 2022 at 1:30-4:00PM ET.
Registration closed. Thank you!
-
We are hosting a tutorial workshop on Wednesday, September 28th, 2022 at 2:00-4:30PM ET.
Registration closed. Thank you!
-
We are hosting a tutorial workshop on Tuesday, April 5th, 2022 at 11:30-2PM EST.
Registration closed. Thank you!
-
We are hosting a tutorial workshop on Thursday, March 3rd, 2022 at 1:30-4PM ET.
Registration closed. Thank you!
- MoSeq Office Hours
- Wednesday, August 16th, 2023 from 1:00PM to 3:00PM ET Zoom Link
- Wednesday September 13th, 2023 from 1:00PM to 3:00PM ET Zoom Link
- Monday, October 16th, 2023 from 1:00PM to 3:00PM ET Zoom Link
- Thursday, November 9th, 2023 from 1:00PM to 3:00PM ET Zoom Link
- Thursday, March 17th, 2022 from 11:00AM to 12:00PM ET Zoom Link
- Thursday, March 31st, 2022 from 11:00AM to 12:00PM ET Zoom Link
- Thursday, April 14th, 2022 from 11:00AM to 12:00PM ET Zoom Link
Primary research papers
- Mapping Sub-Second Structure in Mouse Behavior
- Characterizing the structure of mouse behavior using Motion Sequencing
- Keypoint-MoSeq: parsing behavior by linking point tracking to pose dynamics
Read more about how MoSeq has been used for research
Contact us
![]() Join our Slack channel! For general inquiries or reaching the developers at MoSeq@hms.harvard.edu.
Join our Slack channel! For general inquiries or reaching the developers at MoSeq@hms.harvard.edu.
License
MoSeq is freely available for academic use under a license provided by Harvard University. Please refer to the license file for details. If you are interested in using MoSeq for commercial purposes please contact Bob Datta directly at srdatta@hms.harvard.edu who will put you in touch with the appropriate people in the Harvard Technology Transfer office.